
Dizinin üçüncü kısmında ZFS’in veri güvenliği ile ilgili detaylara girip bazı olası veri kayıplarını gerçekleştirmeyi deneyeceğiz. Kemerlerinizi bağlayın. 🙂
RAIDZ ile veri kaybı senaryoları
Bir önceki makalede en son RAIDZ-1 bırakmışız, onu kullanalım.
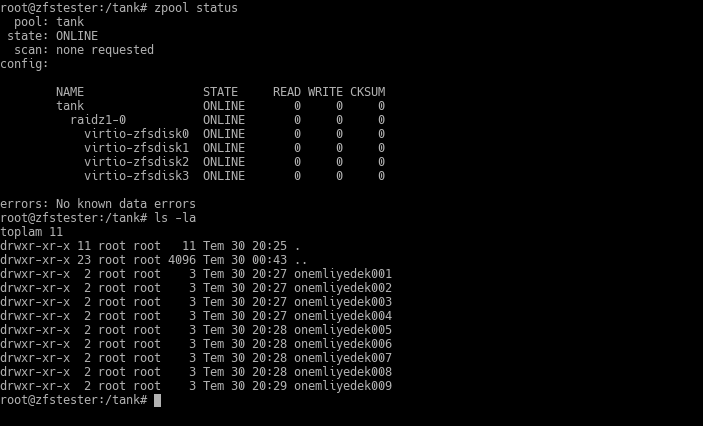
/tank dizini altında erişilebilir hale gelmiş ZFS bölümümüzde 9 tane dizin yarattım ve bunların içine de 400MB büyüklüğünde birer dosya koydum. Bunların ne olduğu önemli değil, ama kaybetmek istemediğiniz veri olduğunu varsayıyoruz. 🙂
Diyelim ki 2 numaralı disk (virtio-zfsdisk2) öldü.
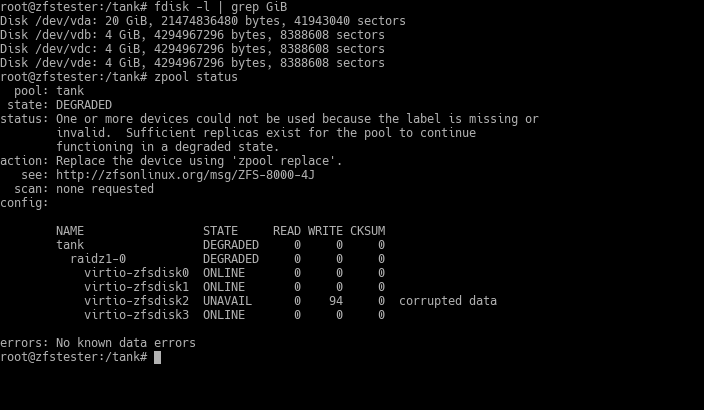
ZFS birkaç dakika içinde bunu saptar ve havuzu “DEGRADED” durumuna getirir. Peki veri ne oldu?
Güvende. Havuzunuz bu şekilde çalışmaya devam eder, hizmette bir kesinti olmaz. Ancak RAIDZ-1 ikinci bir disk arızasını kaldıramaz. Mümkün olduğu kadar çabuk yeni disk takmamız bizim yararımıza.
Burada ufak bir numara çevireceğim. Önceki yazılarda söylediğim gibi, ZFS yazı dizisini bir sanal makinada yürütüyorum. Bu “disk”lerin hepsi de aslında sanal makinanın üstünde çalıştığı konak makinada birer dosyadan ibaret. Aşağıdaki ekran görüntüsü işte bu konağın terminalinden, bizim zfstester makinasına disk diye gösterdiğim dosyaların bir listesi:
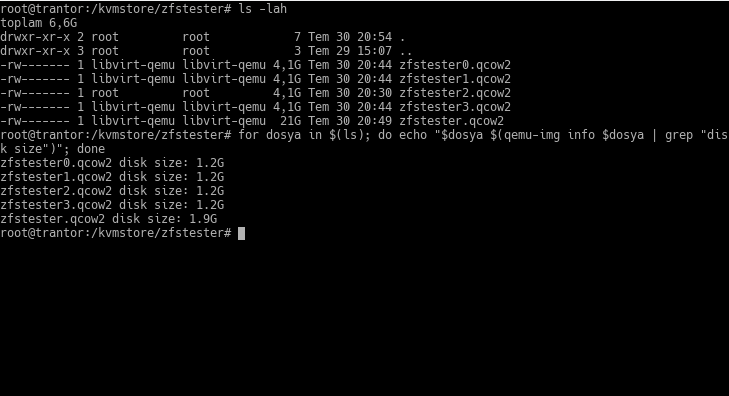
zfstester0.qcow2’den zfstester3.qcow2’ye kadarki dosyalar bizim zfstester makinasındaki 4GB’lık diskleri temsil ediyor -hani size “ben 4GB yaptım siz 4TB varsayın” demiştim ya, onlar. zfsterster.qcow2 dosyası o sanal makinanın işletim sisteminin bulunduğu disk.
Bu qcow2 formatının özelliği biz aksini söylemediğimiz sürece sadece içine koyulan veri kadar yer kaplaması. Dosya listesini aldığımızda bize bir “sanal boyut” bildiriyor. Bizim örneğimizde 4GB. Ancak gerçekte kapladığı alan, içindeki veri miktarı kadar.
zfstester sistemimize ekleyeceğimiz diski, yani konaktaki dosyayı yaratalım ve boyutuna bakalım:
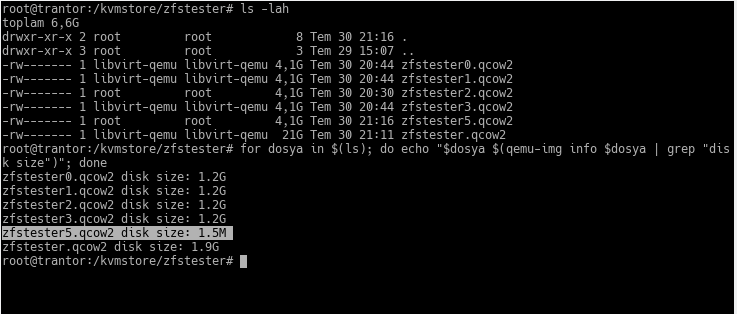
Arkadaşın adını zfstester5 koydum yanlışlıkla. 🙂 ls komutunun çıktısında sanal boyutu 4GB görünüyor. Gerçekte kapladığı alan ise 1.5 MB. İçine henüz veri koymadık, veri koydukça, yani ZFS diğer disklerdeki bilgiyle bunu yeniden oluşturdukça büyüyecek. Ama tıpkı ötekiler gibi 1.2GB kalacak.
Sırada bunu zfstester sistemimize gösterip, zpool status komutumuzun çıktısında bize söylendiği üzere zpool replace komutuyla ZFS VDEV’imize yerleştirmek var.
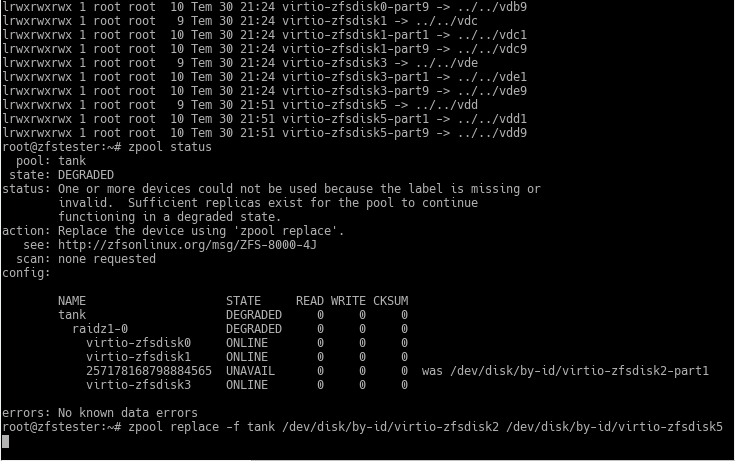
Ekran görüntüsünün üst kısmında /dev/disk/by-id dizininin içeriğine baktım, komut ekran dışına çıkmış. Gerçek bir bilgisayardaki gerçek disklerle bu alan seri numaraları gibi bir tanımlayıcı gösterecek.
Diski ZFS havuzunda değiştirmek için komutum şu oldu:
zpool replace -f tank /dev/disk/by-id/virtio-zfsdisk2 /dev/disk/by-id/virtio-zfsdisk5
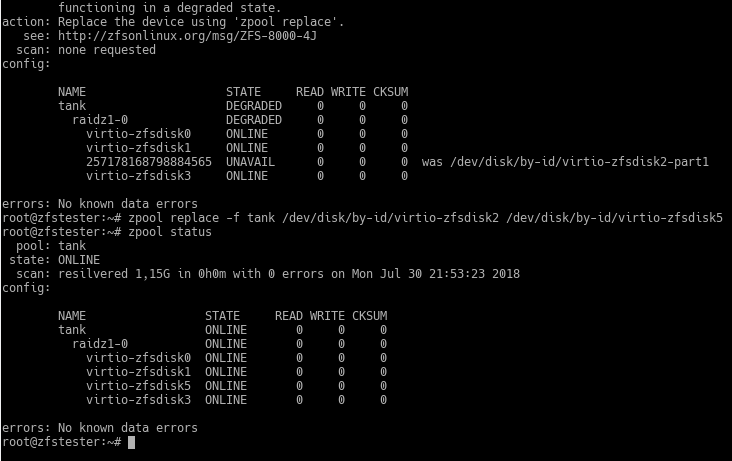
Komutun uzunluğuna bakmayın, disk ID’sini kullanmak istediğim için böyle oldu. Komut beklediğimden kısa sürdü, o yüzden detay yok ama kısa sürüyor diyeyim ben. 🙂 Komut çıktısında “resilvered” ibaresini görüyorsunuz. Bu, havuzdan bozulma gibi bir sebeple çıkarılmış disk yerine takılan bir diskin, diğer disklerdeki verinin kopyalanmasıyla kullanıma hazırlanmasına verilen isim.
Şimdi bir de diskin bozuk olmadığı, ama herhangi bir sebepten verinin bozulduğu durumu deneyelim. Bunun için havuzdaki disklerden birinin bir yerlerine /dev/random’dan rastgele veri yazdım. Normalde bu tip bir durumla karşılaşmazsınız, olsa olsa bir bit hata gelir. Ben basbayağı diskin bir yerlerinden başlayıp keyfi olarak Ctrl+C’ye basana kadar sürdürdüm. Diskin tamamındaki veriyi bozmuş olabilirim. 🙂

Bu tip veri arızaları için ZFS’in kullandığı komut scrub. Yapay hatamı kasten verdikten sonra çalıştırdım ve hemen arkasından zpool status ile durumu gözlemledim. ZFS kısa sürede diskteki veri hatasını saptadı ve düzeltmeye girişti.
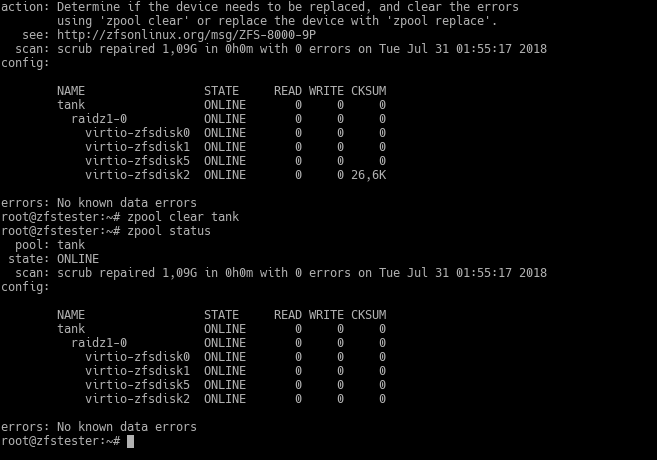
ZFS’in bu disk hatasının kaynağını bilmesi imkansız. Bizim için de bunu bulmak pratik olmayabilir. Dolayısıyla ZFS bize “ya diski değiştir garantiye al ya da kontrol edip hatayı temizle” diye uyarıda bulunuyor. zpool clear komutuyla hatayı silene kadar da bu uyarı gelir. Sildikten sonra ise sanki hiçbir şey olmamış gibi çalışmaya devam eder.
Bunları RAID’le denesene delikanlı!
Daha önce niye RAID yerine ZFS tercih ettiğimi açıklamıştım, şimdi pratik denemelerine sıra geldi. Yazının burasına kadar ZFS’te denediğim şeyleri bir de RAID5 dizisi kurup denedim.
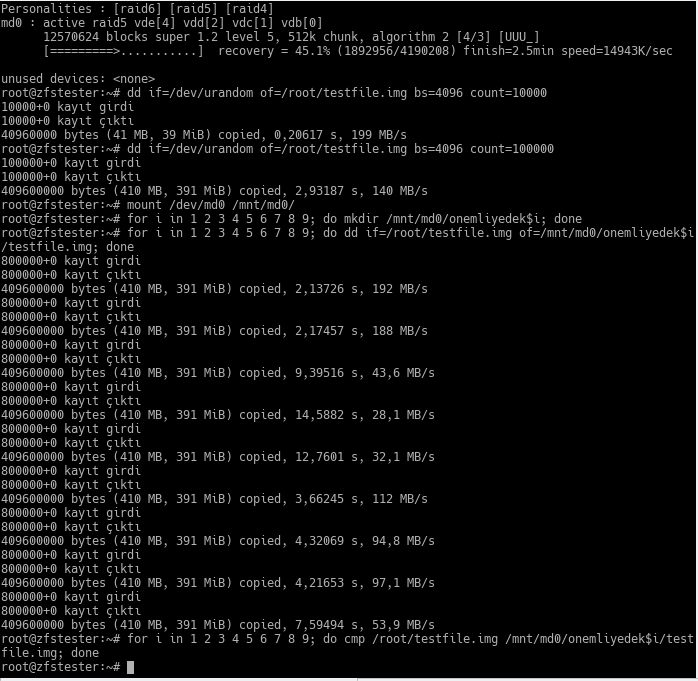
Yukarıda yaptığım test hazırlığı şöyle:
- Önce bir 4 disklik bir RAID5 dizisi oluşturup kontrol ettim
- Sonra kök kullanıcının evinde rastgele baytlardan oluşan 400MB’lık bir dosya yarattım. İlk komutta bir sıfır eksik koymuşum ikincisinde tamamlıyorum.
- Yeni RAID5 dizimde ZFS örneğindeki gibi klasörler yaratıp, bunların içine ilk yarattığım dosyadan birer kopya yerleştirdim
- Son olarak bu kopyaların hepsini ilk dosyayla bayt bayt karşılaştırdım. Fark yok, kopyalar doğru.
İlk işlem bu sistemden bir disk çıkarmak ve yeni, boş bir disk takmak oldu. Bekleyeceğimiz üzere bu bir sorun çıkarmadı; RAID5 yeni taktığım diski başarıyla “rebuild etti”.
Etti etmesine de, ZFS’ten epeyce uzun sürdü? Sebebi RAID’in diski en baştan başlayıp en sona kadar kopyalayarak veri kurtarması. Bunu göstermek için RAID dizisindeki tüm diskleri teker teker değiştirip tamirine izin verdim. Sanallaştırmayı yaptığım ana (konak) makinadaki sonuç şöyle:
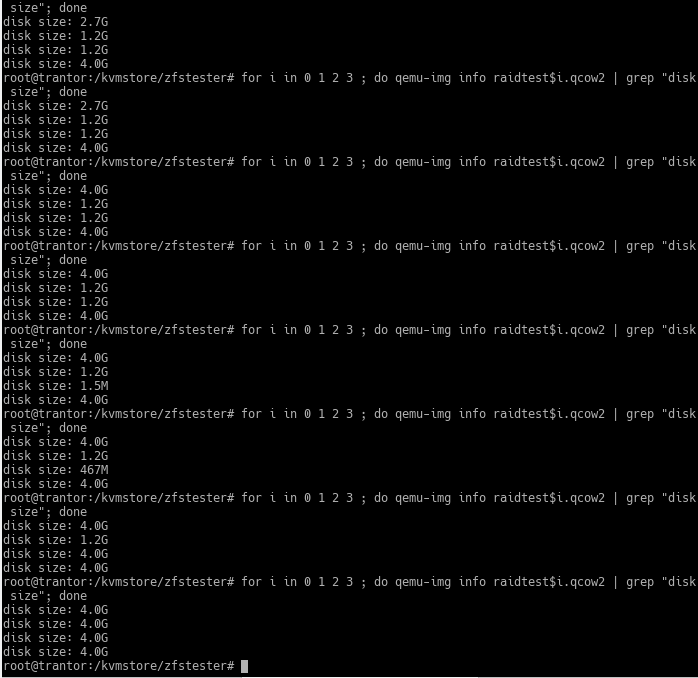
Yeni diskin nerede olduğunu boyutundan rahatlıkla anlayabilirsiniz. 1.5MB olan yeni. RAID sistemi onu doldurmaya başladığında boyutu artıyor. Ancak RAID gerçekten kayıtlı olan veriyi değil, gördüğü diski kopyaladığı ve ona görünen sanal diskin boyutu 4GB olduğu için yeni disk dosyasını boyutu tamamen büyüyor.
Dört diski de sırayla çıkarıp yenileyince, içerideki veri miktarı değişmediği halde hepsi 4’er GB alan kaplamaya başlıyor. Bunun anlamı, 4 tane disk hatasından kurtarmak için 16GB veri aktardım. Bu sırada başka disk arızalanmasın diye bildiğiniz kısa duaları edebilirsiniz. Gerçek hayattaki 4TB ve yukarısı disklerde ise hatim inersiniz.
Bir de sessiz veri bozulmasının benzeşimini yapacaktık; RAID dizimizdeki sanal disklerden bir tanesini kurban seçip üstüne küçük, şirin, rastgele baytlar yazdım. Örnekte kurbanlık diskin adı /dev/vde. RAID doğal olarak bunu farketmedi. Sonuçta üç dosya diğerlerinden farklı durumda kaldı.
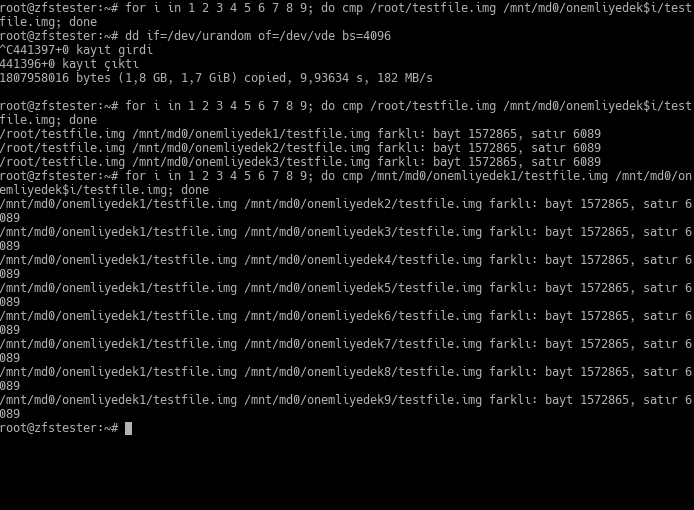
Sonra bir adım ötesine geçip, bozmadığım, sağlam disklerden birini çıkararak yerine yeni ve boş bir tane taktım. RAID bu boş diske veri aktarımını yaptı. Ama yanlış yaptı! Artık tüm dosyalarım birbirinden farklı. Yani tüm dosyalarım bozuldu.
Şimdi “biz yıllardır RAID yapardık bi’şey de olmadı” diyeceksiniz. Çünkü eskiden küçük disklerle uğraşıyordunuz. Bir de şansınız yaver gitmiş ve yöneticilerinizi pahalı depolama sistemleri almaya ikna etmişsiniz. Madde madde özetleyeyim:
- RAID’in amacı diskin tamamen ölmesinden kaynaklı veri kaybını engellemektir
- RAID diskin tamamının ölmediği veya hata vermediği “sessiz” veri hatalarına karşı korumaz
- RAID’de bir disk bozulup değiştiği zaman yeniden yapılandırma diskin başından sonuna kadar olur. Bu nedenle:
- RAID dizisindeki diğer disklere aşırı yük biner. Bazı durumlarda bu yük o disklerin tasarım spesifikasyonlarını geçebilir. Yani RAID yeniden yapılandırması boyunca diğer disklerin de arıza çıkarma ihtmalleri artar
- Dizinin tekrar yapılandırıldığı süre uzadığı için diğer disklerin arıza çıkarmaları ihtimali daha da yükselir.
Sırf bu yazı bile ZFS kullanmak için yeterli sebep aslında. Not olarak, RAID5’in artık önerilmediğini belirteyim. RAID yapacaksanız bile RAID5-6 vb. değil, RAID10 (RAID0+1) yapın.
Hangi ZFS topolojisini kullanalım?
Bir önceki yazıda aynalamalı ve RAIDZ topolojilerini göstermiştim, bu yazıda RAIDZ üzerinden nasıl olduğunu örnekli açıkladım. Benim tercih listem şöyle:
- RAIDZ1 pek kullanmak istemiyorum, şimdiye kadar da kullanmadım. Sebebi ikinci disk arızasında veri kaybı ihtimalinin %100 olması. RAIDZ olacaksa RAIDZ2 veya 3 olmalı.
- 4-6 diske kadarki sistemlerde aynalanmış konfigürasyonu tercih ediyorum. Makul bir depolama kapasite oranına karşılık ikinci ve daha ileri seviye disk kayıplarında bir şansım olduğuna inanıyorum. Ayrıca resilvering işleri hızlı oluyor.
- 8 diskten itibaren RAIDZ2’yi düşünülebilir buluyorum. Böyle bir sistemin varlık sebebinin depolama olduğunu düşünebiliriz. E kasadaki disk yeri ve anakarttaki SATA/SAS yuva sayısı sınırlı olabilir. Yine öncelik aynalanmış konfigürasyon; bunun depolama yoğunluğu yeterli gelmiyorsa RAIDZ2.
- RAIDZ3’ü hiç düşünmedim şimdiye kadar. Belki de o kadar büyük depolama boyutlarına henüz hiç girmediğimdendir. Ama bu RAIDZ seviyeleri ilerledikçe disk resilvering süreleri doğrusal değil ivmeli artıyor.